RAG Library
RAG Technology
RAG (Retrieval-Augmented Generation) is a technology that combines information retrieval and text generation. Its core idea is to allow the generation model to actively retrieve relevant information from external libraries when answering questions, thus generating more accurate and reliable answers.
RAG technology can effectively address many limitations of large language models:
- Knowledge Limitations: The breadth of a model’s knowledge heavily depends on the breadth of its training dataset. Most large models on the market use publicly available datasets from the web, which means they lack access to internal data or highly specialized knowledge from specific fields.
- Knowledge Lag: The knowledge of a model is acquired through training with the dataset, but any new knowledge generated after the model has been trained cannot be learned. Additionally, training large models is very costly, so it's not feasible to retrain them frequently to update their knowledge.
- Hallucination Issue: All AI models are based on mathematical probabilities, and their outputs are essentially a series of numerical calculations, including large models. Sometimes they may generate nonsensical answers, especially in areas where the model lacks knowledge or is not skilled. Identifying hallucinations can be difficult because it requires the user to have domain-specific knowledge.
- Data Security: For businesses, data security is crucial. No company wants to risk data leaks by uploading their private data to third-party platforms for training. This also forces applications relying solely on generic large models to make trade-offs between data security and effectiveness.
RAG Workflow
We can divide the RAG workflow into five stages:
- Vectorization Stage: The task in this stage is to convert text into high-dimensional vectors using embedding models and save them into a vector database.
- Library Selection Stage: Based on the user's question, the system uses the capabilities of large language models to select the appropriate library. This technology is also known as Query Routing.
- Recall Stage: Also known as the retrieval stage, in which the user's question is vectorized, and the most relevant content is searched for in the high-dimensional vector space of the vector database.
- Post-Processing Stage: After recalling multiple context fragments, appropriate processing is done before submitting them to the large language model for generation.
- Generation Stage: The large language model generates appropriate text based on the retrieved context fragments.
The Gendial platform provides rich configuration options at each of these five stages, allowing for the optimal RAG performance based on the specific needs and document content.
Vectorization Stage
In this stage, users can choose different vector models and vectorization strategies.
Vector Model (Embedding Model) is one of the core components of the RAG system, and its performance directly affects the final output of RAG. Its main function is to convert text (questions, document fragments, etc.) into high-dimensional vectors (Embeddings), which reflect semantic relationships through mathematical distances (such as cosine similarity). A good vector model can match questions with relevant document fragments more accurately, avoiding missed or incorrect matches.
The Gendial platform offers two vector models:
- BGE-M3: BGE-M3 is a new embedding model developed jointly by the Beijing Artificial Intelligence Research Institute and the University of Science and Technology of China, specifically optimized for RAG systems. Its strengths include multilingual support, multifunctionality, and multi-granularity, supporting over 100 languages and performing various retrieval functions. It can handle input from short sentences to long documents and performs excellently in multiple benchmark tests.
- OpenAI text-embedding-3: Provided by Microsoft's Azure OpenAI services, this model can accurately interpret complex user queries and quickly retrieve highly relevant information from the library, greatly improving retrieval efficiency and relevance. The embeddings it generates have precise semantic understanding, enabling large language models to generate more fitting, accurate, and detailed responses, thus enhancing overall RAG system performance.
Additionally, if users have better vector model options, they can integrate new models into the library system through large model management.
Different document content often requires different vectorization strategies to achieve better vectorization results. A vectorization strategy is used to achieve better vectorization by configuring different document chunk sizes, overlap sizes, and adjusting specific content for vectorization based on document content and nature.
The Gendial platform offers four vectorization strategies that can effectively handle different document properties and content:
- Original Text Chunking Vectorization
- Parent-Child Chunking Vectorization
- Chunk Summary Vectorization
- Hypothetical Question Vectorization
For detailed descriptions of the vectorization strategies, please refer to the Vectorization Strategy chapter.
Library Selection Stage
When you ask an AI agent about international politics, you wouldn't want it to search for answers in a recipe database. Similarly, when your users ask your smart customer service bot about product performance, you wouldn't want it to search through the company's HR policies. Therefore, different types of documents should be stored in separate libraries. Then, based on the user's query, the system can search the corresponding library.
On the Gendial platform, you can configure the library selection strategy (also known as Query Routing) in the AI agent’s library settings. An agent can be associated with multiple different libraries, and when answering a question, it can use the content of the query, the description of the library, and the configured selection strategy to find the appropriate library for retrieval.
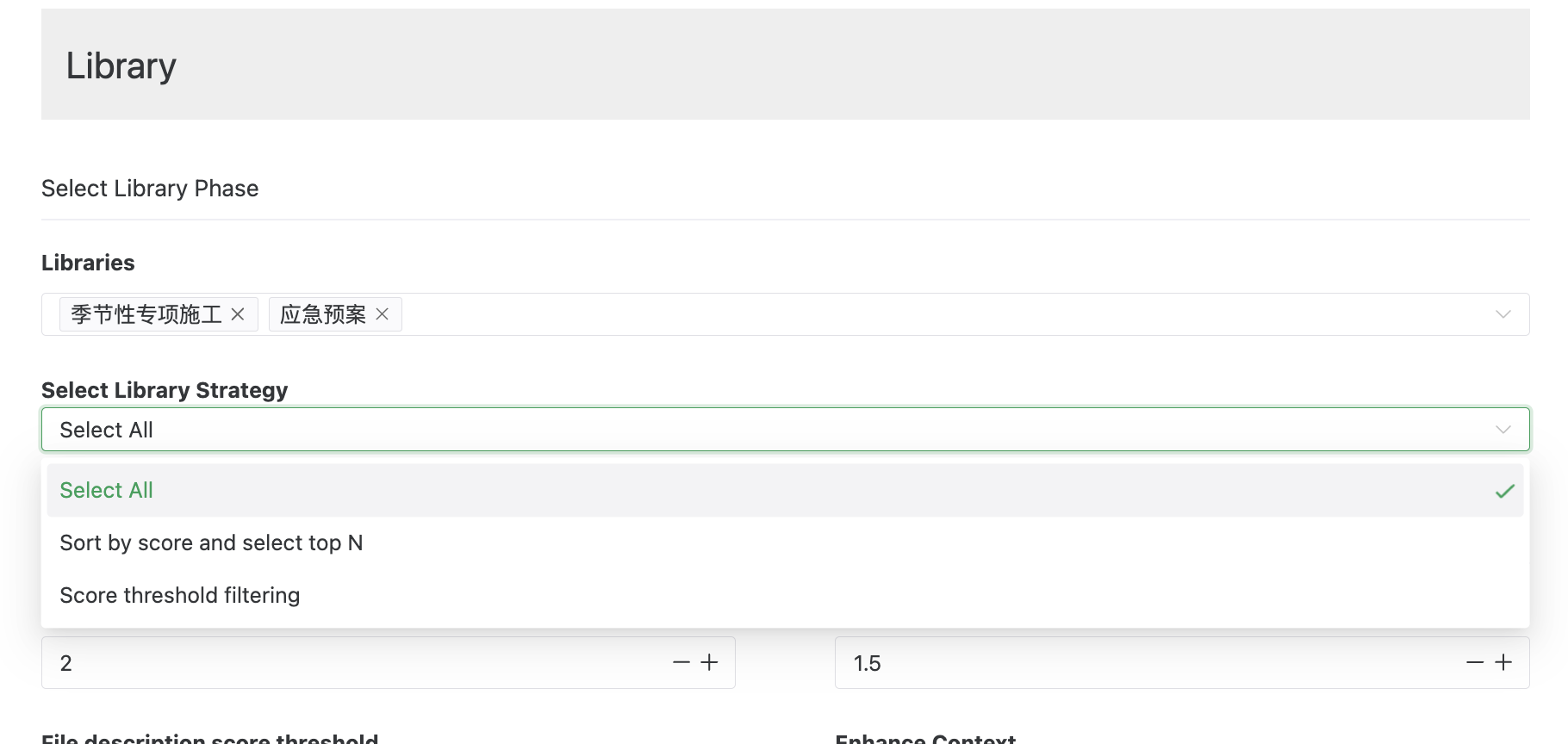
For a detailed explanation of the library selection strategy, refer to the [AI Agent Library Strategy] chapter.
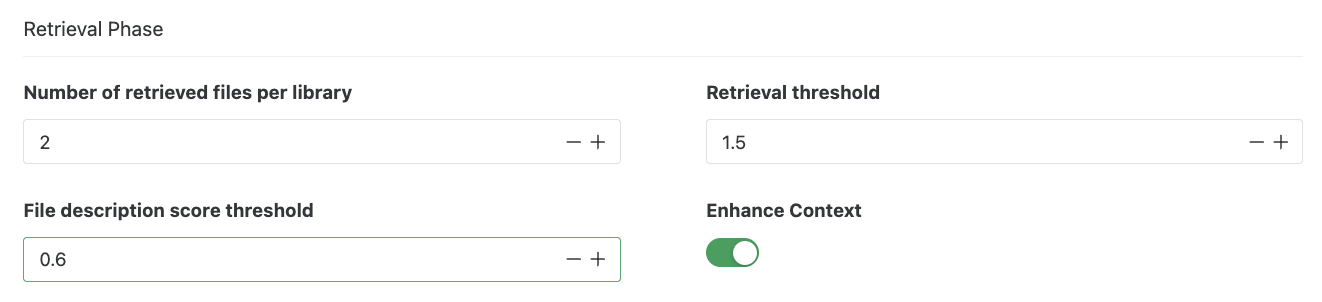
Retrieval Stage
Also known as the search stage. In this stage, you can configure the number of context fragments retrieved from each library, set the minimum vector similarity threshold (for vector libraries), or set the minimum file description score (for document libraries). You can also enable the Enhanced Context option to recall the previous and next contexts of the hit context. For detailed explanations, refer to the [AI Agent Library Strategy] chapter.
In the recall stage, another setting that can affect the retrieval results is reorganizing the query during multi-turn conversations in the AI agent settings. This setting allows the large language model to reorganize the user's question, replacing natural language or pronouns with more complete and explicit queries before performing library retrieval. For more information, refer to AI Agent Settings.

Post-Processing Stage After Recall
After recalling relevant context fragments from the library, you can use the large language model to rank and filter these fragments based on specific strategies before submitting them for the final answer generation. The benefits of this approach include:
- Avoiding Disruptive Information: Library retrieval always finds some relevant content, but how relevant is it? We refer to irrelevant data points as "disruptive items." They can make the results confusing and even mislead the model.
- Reducing Context Length: Too long a context can affect the large language model’s response time and incur unnecessary token costs.
The model used in the post-processing stage can differ from the one used for text generation. Smaller, faster models like GPT-4o mini or Doubao 1.5 lite are usually recommended.
Generation Stage
When the large language model obtains the appropriate context and answers, some settings can make the generated information more useful:
- Context Metadata: Each context fragment provided to the large language model is accompanied by metadata:
- Library Name
- Library Description
- Source Document Name
- Source Document Description
These metadata can be configured in the library and document. With these metadata, the large language model can know the library and document associated with the context fragment, improving the quality of the answer.
- Show Reference Original Text: In the output information node, you can set whether to display the original text that the large language model referenced for its answer. With these references, users can know the source of the large language model’s answers, increasing their confidence in adopting the answers.