RAG Performance Evaluation
As mentioned earlier, the Gendial platform provides a rich set of configuration options for the entire RAG process, allowing adjustments based on different document characteristics and business needs. But how can we evaluate whether the library and configured strategies are working as expected? That's when you need the right testing tools.
Retrieval Testing Tool
The Gendial platform offers a recall testing tool that can test the effectiveness of various stages of the process, from selecting the library to post-recall processing.
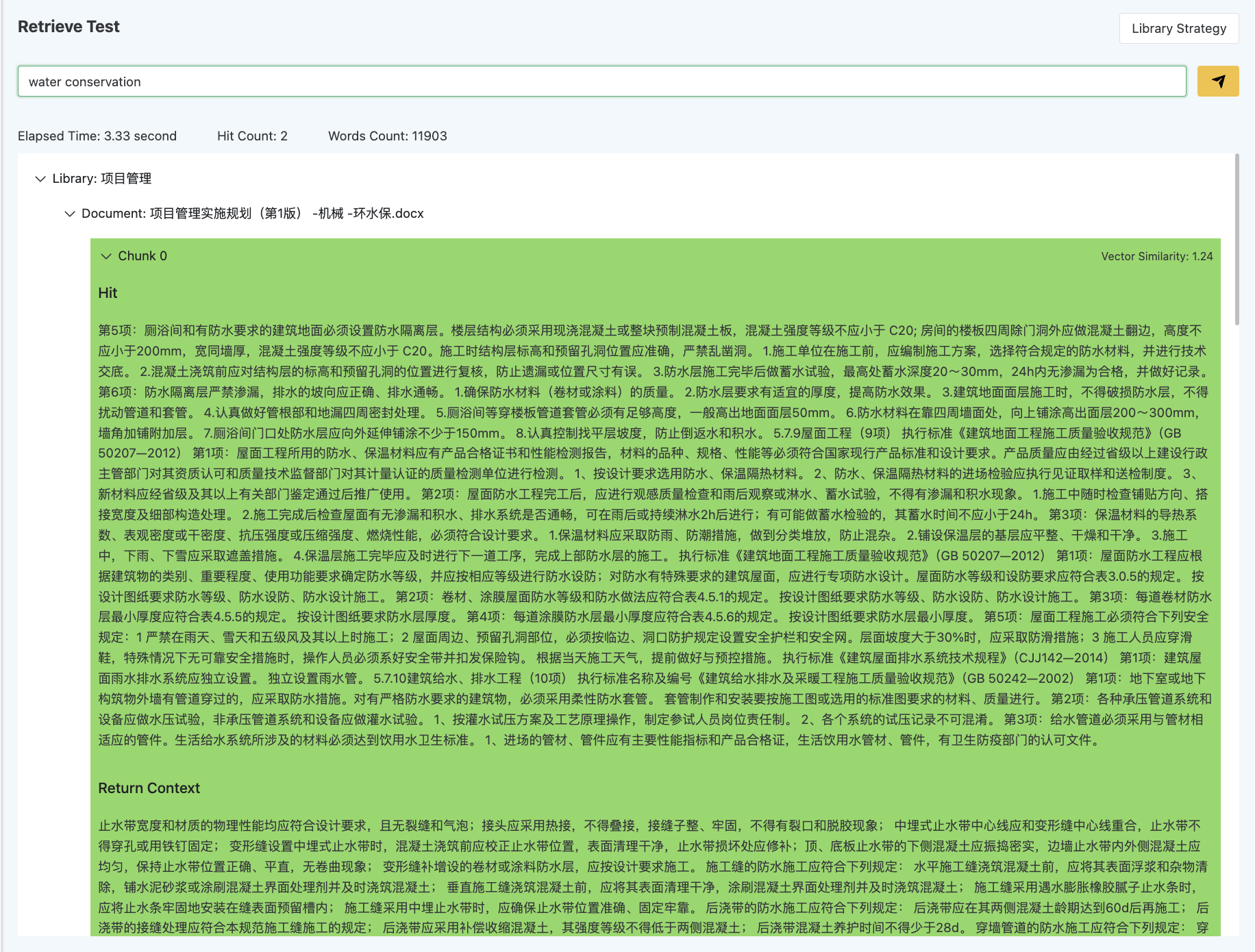
The recall testing tool can evaluate:
- Whether the vectorization strategy for the vector library is effective
- The large language model's understanding of the library description and document descriptions
- The selection strategy for multiple libraries
- Different recall strategies
- Post-recall processing strategies
The recall testing tool reveals key information in the RAG process:
- Total query time: The total time taken for the entire query
- Hit document fragments: The specific document slices and their count that were hit
- Returned context: The specific context returned (under the parent-child chunk vectorization strategy, when multiple child segments are hit, only the parent segment is returned; when enhanced context is enabled, both preceding and succeeding segments are returned)
- Vector similarity of the hit context: (Applicable only to the vector library) Shows the vector similarity of the segment, which can be used to adjust the recall strategy's vector similarity threshold.
- File description score of the hit document: (Applicable only to the document library) Shows the file's large language model score, which can be used to adjust the recall strategy's file score threshold.
💡 Tip: Start by setting smaller vector similarity and file score thresholds in the recall strategy configuration to ensure that at least some document segments are found, then gradually increase the threshold to exclude irrelevant segments and improve recall efficiency.
Using Gendial Agents for Automated Evaluation
While the recall testing tool provides valuable insights when testing single-query strategies such as vectorization and recall, it is inefficient for evaluating statistical results across a large number of questions and outcomes.
The simplest approach is to ask a group of people to score the answers—for example, have 1000 people evaluate if the large model's response is helpful. This way, you’ll get a rough idea of its performance. But honestly, this approach is unrealistic and not sustainable over time.
Moreover, every time you tweak the RAG system, the results might change. I know how hard it is to get domain experts to test your system. Maybe you can manage one or two tests, but you can't go asking experts every time you make small adjustments, right?
So, we need to come up with a smarter way. One idea is to skip the humans and use agents to evaluate the results—this is the "let agents be the judges" method. This way, you save time and effort, and you can test anytime, how convenient!
Using the Gendial platform, you can create an automated agent to assess RAG performance. Below are the basic steps to implement this:
- Provide an evaluation dataset: Prepare some questions and answers to test the RAG agent’s performance.
- Define an evaluation standard: Evaluation criteria can be based on business requirements, such as loyalty, relevance, completeness, etc. Set appropriate prompts for each criterion and use another (usually more powerful) large model for evaluation.
- Create an automated evaluation agent: This agent is responsible for reading each question, submitting it to the RAG agent with evaluation capabilities to generate an answer, and then submitting the generated answer along with the pre-set answer to the evaluation large model node for assessment.