RAG性能评估
如前所述,煎蛋平台针对整个RAG流程提供了丰富的配置选项,可以按照不同的文档特性和业务需求进行设置。但是如何评估我们搭建的知识库和配置的策略是否按照我们希望的效果进行工作了呢?这时候你就需要合适的测试工具。
召回测试工具
煎蛋平台提供一个召回测试工具,可以测试从选库到召回后处理的各个阶段的效果。
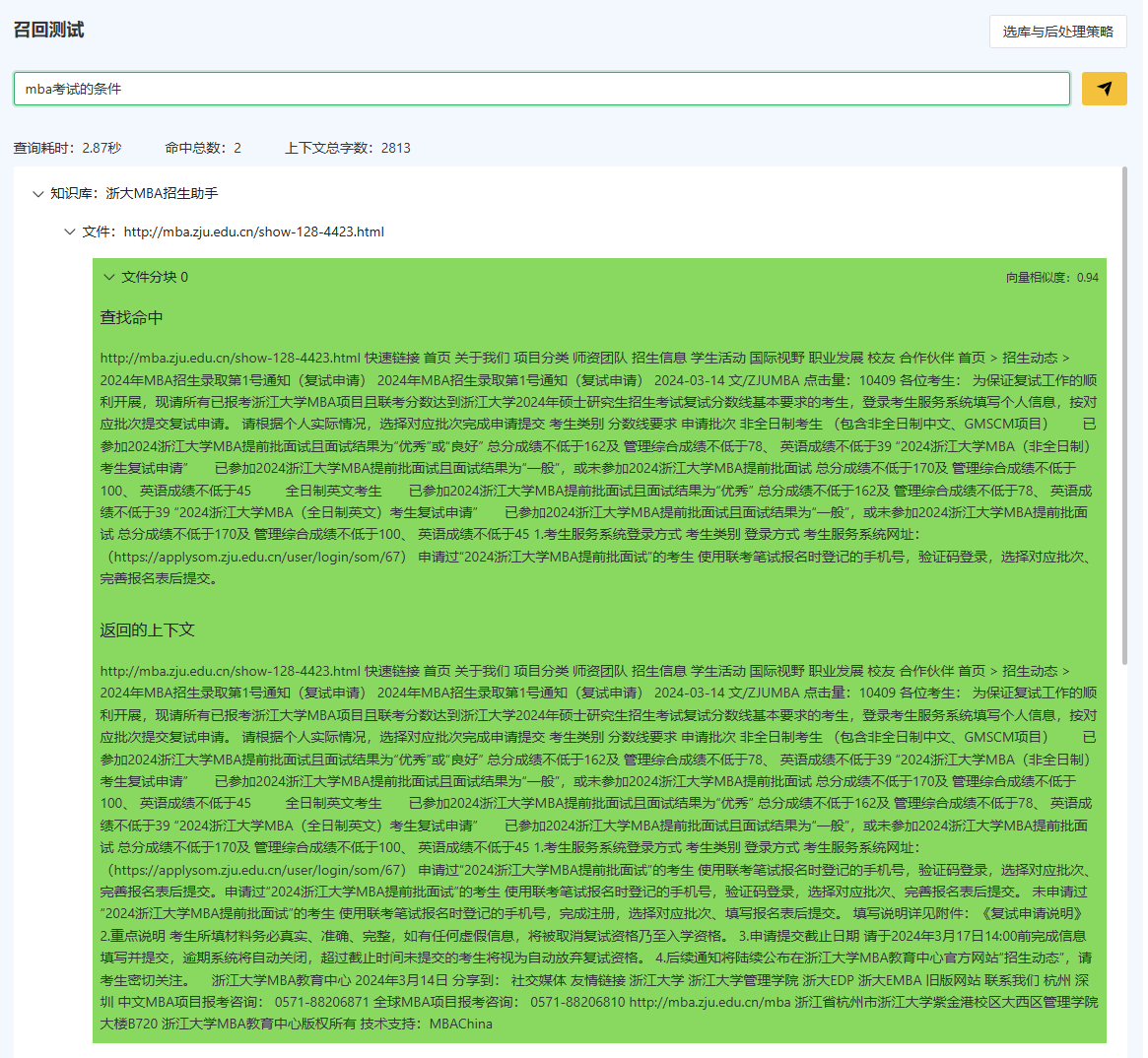
召回测试工具可以测试:
- 向量库的向量化策略是否有效
- 大语言模型对文件库的知识库描述和文件描述的理解效果
- 多个知识库的选库策略
- 不同的召回策略
- 召回后处理策略
召回测试工具揭示了RAG过程中的关键信息:
- 整体查询的耗时:整个查询的总耗时
- 命中的文档片段:命中的具体的文档切片内容和数量
- 返回的上下文:具体返回的上下文内容(在 父子分块向量化策略 下,多个子分段同时命中将只返回同一个父分段;开启 增强上下文 时将同时返回前后分段 )
- 命中的上下文的向量相似度:(仅对向量库有效)显示了该分段的向量相似度,可以用来调整召回策略的 向量相似度 阈值。
- 命中的文件描述评分: (仅对文件库有效)显示了该文件的大语言模型评分,可以用来调整召回策略的 文件评分 阈值
💡 小贴士::一开始可以在召回策略配置较小的 向量相似度 和 文件评分 阈值,确保至少能够找到一些文档分段,然后再逐步增加这个阈值把不相关的文档分段排除出去,可以增加召回的效率。
利用煎蛋智能体来自动评估
虽然召回测试工具在测试单次查询的向量化策略、召回策略等策略时能够提供不少洞见信息,但是在评估大量的问题和结果的统计结果时效率太低。
最简单的办法就是找一堆人来打分——比如让 1000 个人来评价大模型的回答有没有帮助。这样你就能大概知道它的表现如何了。但说实话,这种方法太不现实了,根本没法长期用。
而且,每次稍微调整一下 RAG 系统,结果可能就不一样了。我知道,想让领域专家来测试你的系统有多难。可能测试一两次还行,但总不能每次改点东西都去找专家吧?
所以,我们得想个更聪明的办法。其中一个思路就是:不用人,而是用智能体来评估结果——这就是“让智能体当裁判”的方法。这样一来,既省时又省力,还能随时测试,多方便!
利用煎蛋平台,你可以创建一个自动化处理流程的智能体,来评估RAG的性能。一下是实现的基本步骤:
- 提供评估数据集: 准备一些问题和答案,用来测试RAG智能体的表现。
- 定义一个评估标准:评估标准可以从业务端的要求来考虑,比如 忠诚度, 相关性,完整度 等等,每一条标准设定合适的提示词,利用另一个(通常是更强大的)大模型来进行评估。
- 创建一个自动化评估智能体: 这个智能体负责逐条的读取问题,把问题提交给带评测的RAG智能体,让它生成答案。然后再把生成的答案和预先设置的答案提交给评估大模型节点进行评估。