编程基础
虽然煎蛋平台可以使用拖拉拽完全无代码的方式实现简单的智能体流程,但是如果你了解以下基本编程的思想和技巧,你创建的智能体将能够更灵活的处理复杂的业务逻辑,实现以前需要完全定制化开发程序才能实现的功能。
变量
在煎蛋平台,你可以定义变量,把节点输出内容保存在变量里,以供后续节点用{{变量名}} 格式来引用,或者保存在后台数据库里进行存档。变量总是字符串类型,可类比人与人之间的自然语言对话。具体参见变量这一章内容。
变量的初始值
有些时候变量需要设置初始值,比如用来控制循环的变量 n。你可以在开始节点里设置变量的初始值。

环境变量
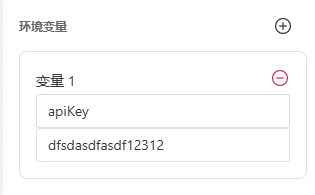
你还可以在开始节点里设置智能体的环境变量,比如apiKey或者其他用于控制流程的变量。环境变量也是同样的用{{变量名}} 格式来引用。
赋值
大部分节点都可以定义输出变量。节点的所有输出内容都会保存在这个变量里,相当于对这个变量进行赋值。 多个节点可以定义同一个输出变量名,相当于编程时对同一个变量多次赋值
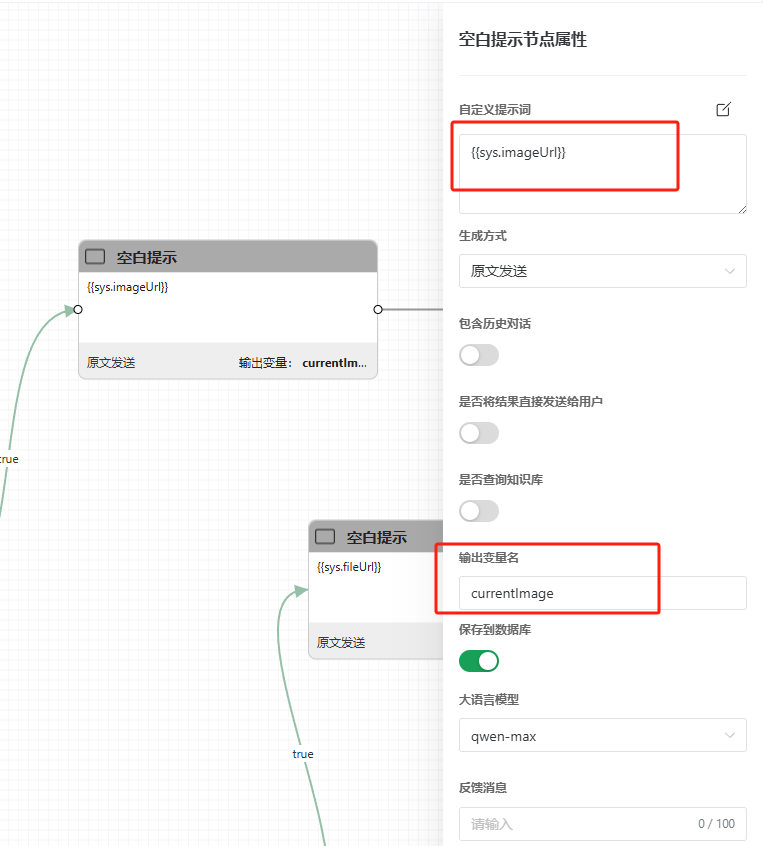
如果你需要把确定内容赋值到变量里,可以使用输出/空白节点的“原文发送”模式,如下图的意思是把用户最后一次上传的图片链接保存在名字为currentImage的变量里
你也可以使用代码节点,来对变量进行计算之后再赋值。如下面的节点的意思是计算 n = n +1
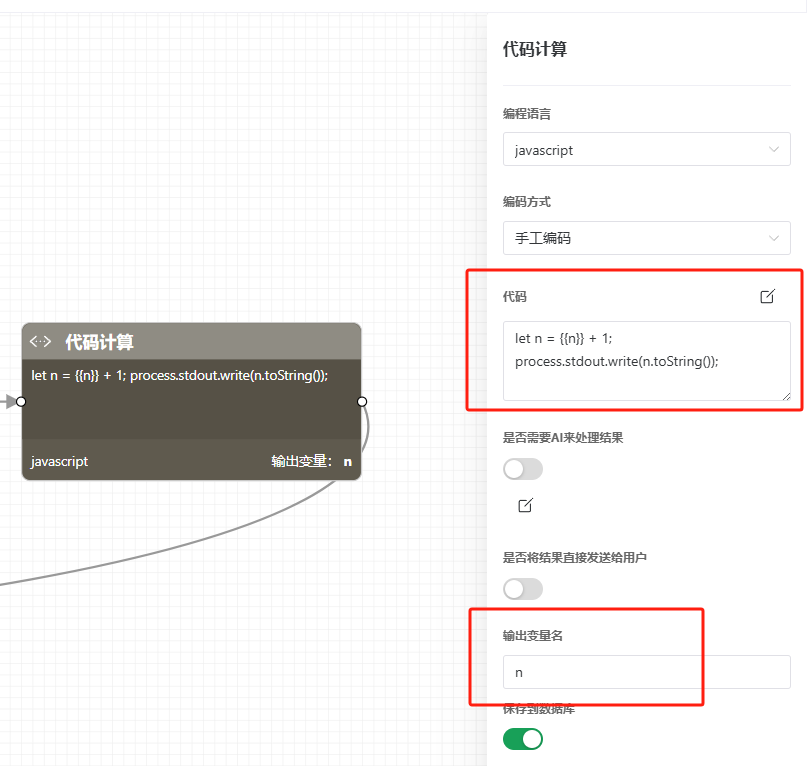
{{变量名}} 的格式会把变量的内容(字符串)直接替换到提示词或者代码里,所以图中的代码在替换之后就是以下的代码,
// 假设当前n的值为100
let n = 100 + 1;
process.stdout.write(n.toString());代码执行之后101就会被赋值到变量n里
字符串处理
如前所述,在提示词或者代码里引用{{变量名}} 会把当前变量的内容(字符串)直接替换到提示词或者代码里。如果要把变量内容当作可以被代码处理的字符串表示应该如何做呢?你可以用以下的javascript代码来表示
// 使用`` 或者 "" 或者 ''把变量包围起来
const str = `{{var}}`;如果使用python,可以这么做
str = "{{var}}"💡 小贴士: 有时候你可能需要在代码节点里处理大模型生成的JSON对象,而大模型生成JSON对象时倾向于添加```json这样的markdown格式开头和结尾,导致如果用 `` 来加载字符串时出现格式问题。这时候你可以用" " 或者 ' ' 来处理,也可以让大模型不要添加markdown格式的开头和结尾。比如你可以用这样的提示词:
你的输出必须是完整JSON object对象,不需要添加任何额外的解释或者文字,也不要用```json这样的markdown格式来包裹你的输出。
分支
在煎蛋平台你可以使用判断节点来实现程序分支,可类比 IF-ElSE 和 SWITCH-CASE语句。并且判断节点还可以实现模糊语义判断。
判断节点可以处理以下各种判断逻辑和场景
模糊语义判断
利用大语言模型的能力,根据语义判断选择合适的分支。比如,根据用户的问题,判断他是需要查询订单信息、咨询商品信息、退换货服务等。
确定的逻辑判断
不同于语义判断的模糊性,有时候的判断条件是非常清晰的逻辑关系,这时候用大模型来做判断并不合适:
- 大模型的输出不稳定,在某些情况下一些非常简单的逻辑都有可能判定错误,比如"9.11 和 9.9 谁大"。
- 大模型判断需要花费额外的token和时间成本
这时候就可以使用布尔函数(类比IF-ELSE)或者分支语句(类比SWITCH-CASE)来处里固定清晰的逻辑判断。
判断类型为布尔函数的判断节点,根据返回的真/假 (true / false)值来选择分支。判定节点的内容为布尔函数的函数体,函数体不需要定义函数名,只需函数内部代码,并且最后return 语句返回真假值。比如布尔函数的判断节点里可以这么来判断"9.11 和 9.9 谁大":
return 9.11 > 9.9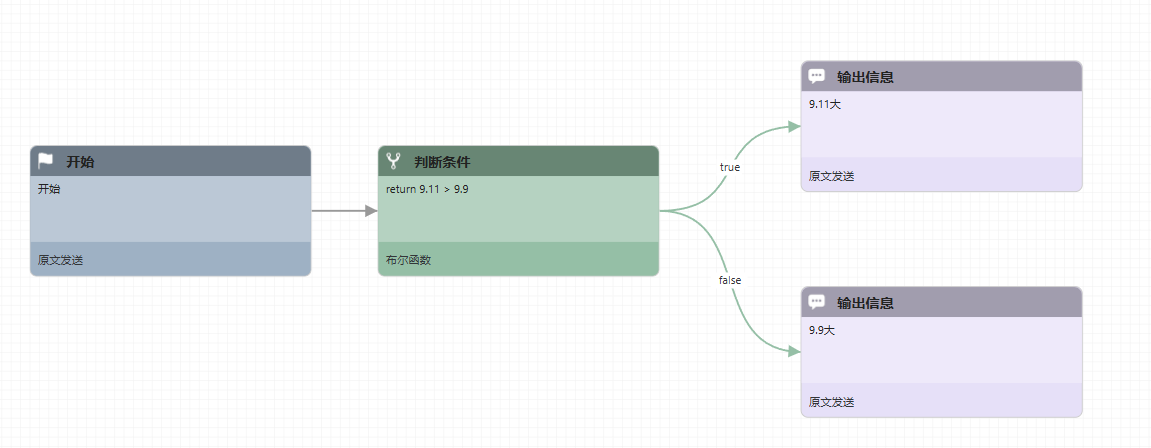
判断类型为分支语句的判断节点,根据所选变量的值来选择分支。所选定的变量必须是前面流程节点输出的自定义变量。变量的值会被当做字符串与判断节点的每一条出口边上的预设的值进行比较,选择值相同的分支。下面的流程图是配合输入节点的预选项输入,来明确的选择确定的分支。
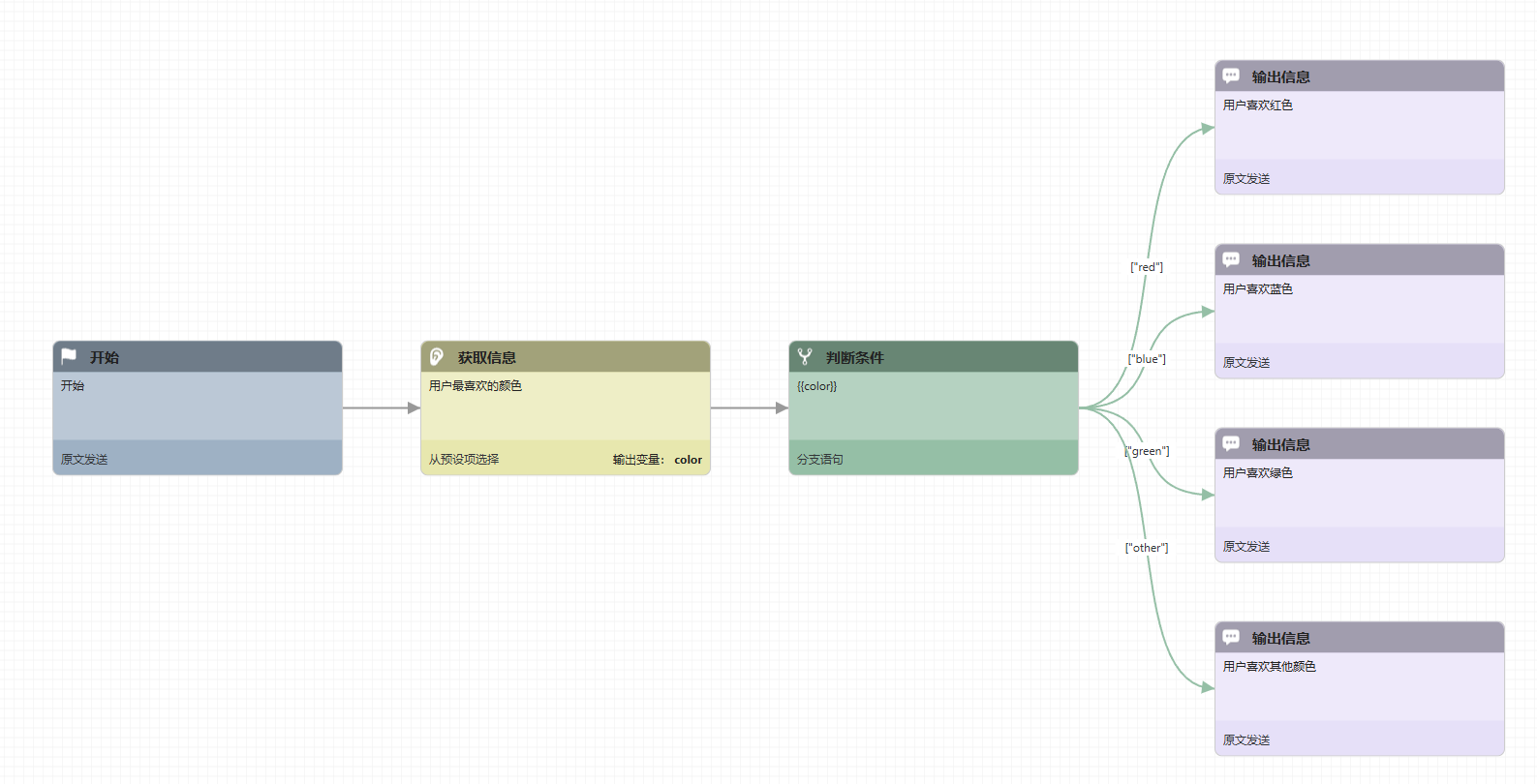
循环
在煎蛋平台上你可以轻松的实现各种循环,可以类比 For循环, while循环 等等。
比如利用前面提到的赋值和判断节点,我们可以这样来实现一个For循环。
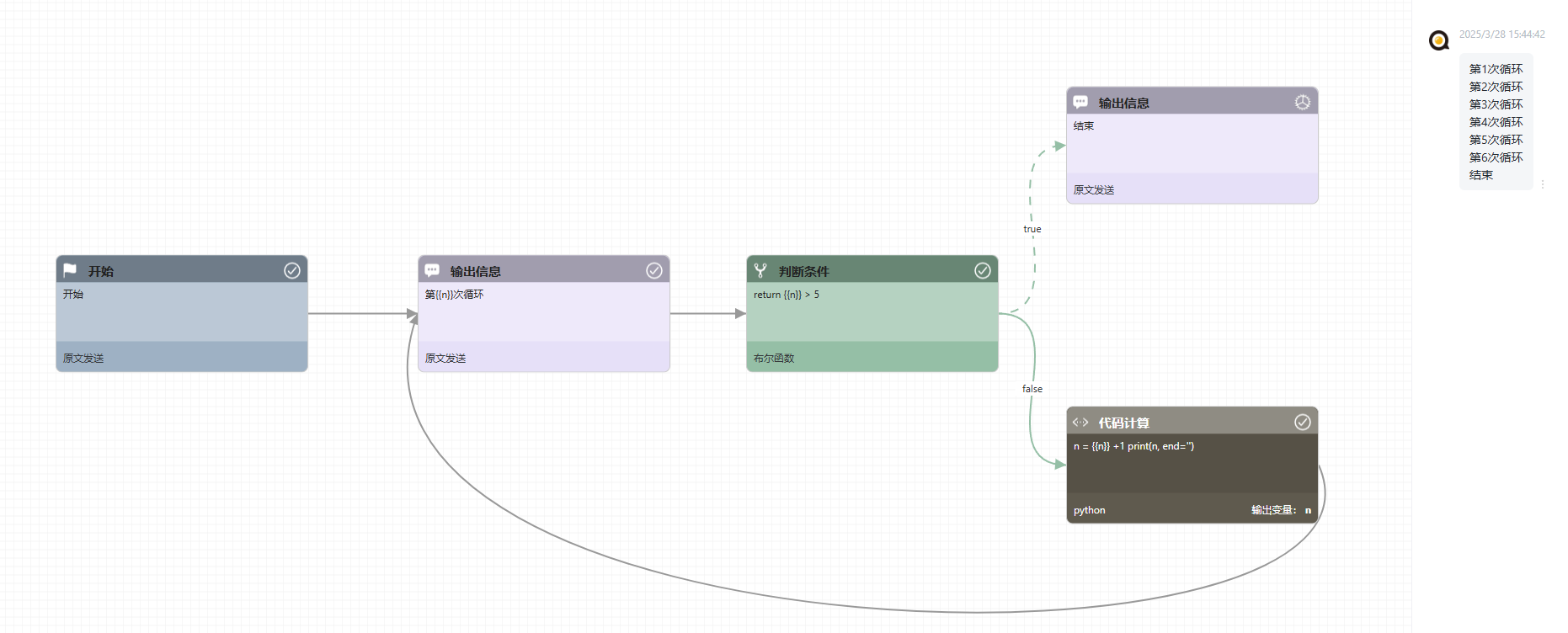
💡 小贴士:
- 可以在开始节点里设置循环控制变量的初始值
- 如果不小心流程定义错误出现了死循环怎么办? 不用担心,平台缺省设定了智能体无需交互可以执行的节点数目为20个。所以即使不小心定义了死循环的流程,在执行20个节点之后就会被强制中断。如果你的业务明确需要自动处理大量的数据,自动循环执行很多节点,你可以把这个缺省值调整到合适的大小:

并发
煎蛋平台支持并发的流程处理,特别适合处理异步的请求。比如可以同时查询多个数据库/业务系统,可以大大的提高处理的速度;或者使用不同的提示词来总结同一段文章的内容,最后把结果整合再让大语言模型回答,往往能够获得更好的效果。这种思路在数据科学里其实很常见。比如在 Boosting 算法中,我们通常会用到一堆简单的模型,每个模型都稍微有点不同,各自做一个小决策。最后,我们再把这些结果整合起来。这种方法效果通常很强。
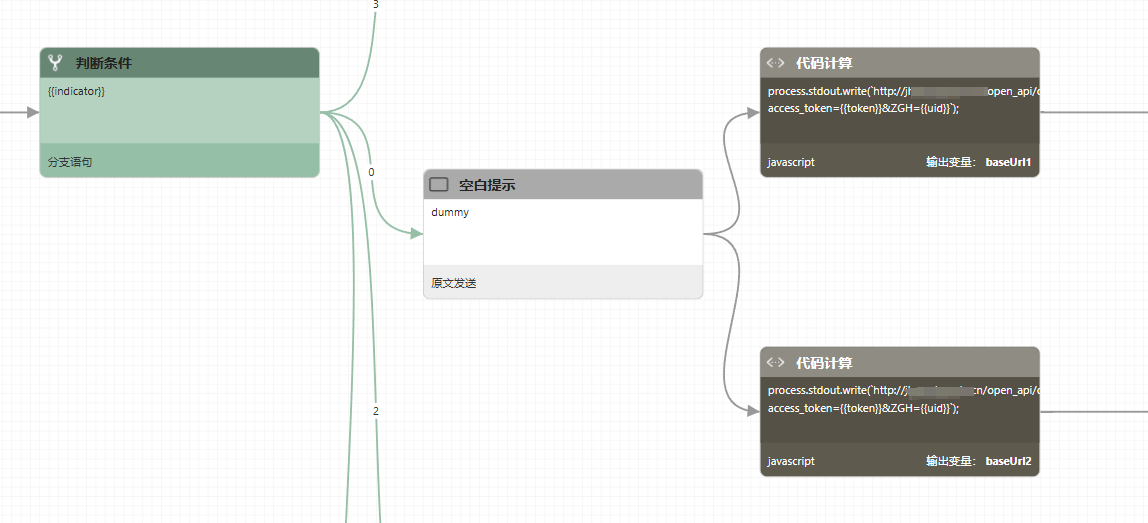
开启并发的流程也非常简单,只需要在前置节点(前置节点不能是判断节点)的拉出多条分支,这些分支都会被并行处理。 对于并发处理的结果,你需要使用一个判断节点来收敛。这个判断节点需要选择 并发后续条件 类型,并且可以选择是否等待所有分支完成还是任意分支完成。
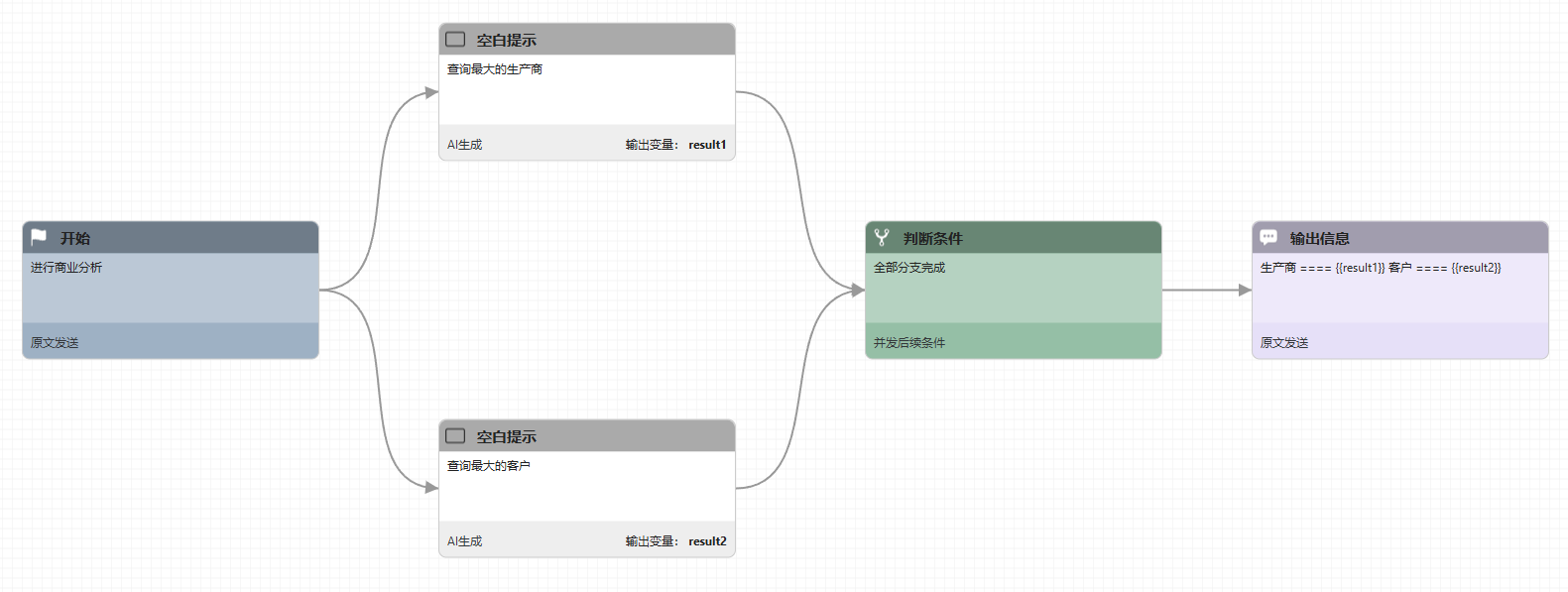
💡 小贴士: 如果想要在判断节点之后马上进行并发操作应该怎么办?这里可以用一个什么都不做的空白节点(或者叫dummy节点)来接到判断节点之后开启并发操作。空白节点的生成方式要选择 原文发送 ,提示词可以留空或者任意文字。这个节点相当于程序语言的no-op语句,即No Operation。