知识库
煎蛋平台包含强大灵活的知识库系统,可以满足大部分企业内部知识库需求。
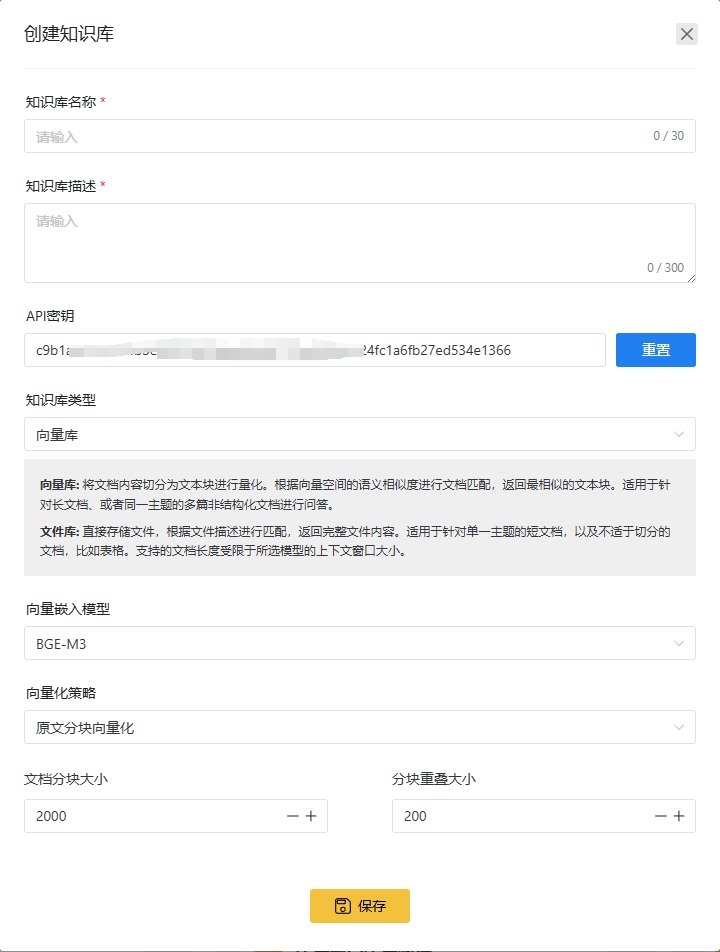
知识库设置
知识库名称
知识库名称除了方便识别之外,还有两个用处:
- 在智能体关联多个知识库时,知识库名称会作为重要的AI选择合适的库的判断条件
- 知识库名称会作为RAG上下文的一部分传递给AI大语言模型
所以尽量起一个合适的知识库名称很重要
知识库描述
描述知识库所包含的内容。同知识库名称,知识库描述也有两个重要的用处:
- 在智能体关联多个知识库时,知识库描述会作为重要的AI选择合适的库的判断条件
- 知识库名称会作为RAG上下文的一部分传递给AI大语言模型里
所以尽量用准确语言来描述知识库,将会提高RAG的质量
API密钥
API密钥是在使用知识库相关API时作为鉴权(bearer token)使用
知识库类型
煎蛋平台的知识库分为向量库和文件库两种形式。
向量库:将文档内容切分为文本块进行量化。根据向量空间的语义相似度进行文档匹配,返回最相似的文本块。适用于针对长文档、或者同一主题的多篇非结构化文档进行问答。
文件库:直接存储文件,根据文件描述进行匹配,返回完整文件内容。适用于针对单一主题的短文档,以及不适于切分的文档,比如表格。支持的文档长度受限于所选模型的上下文窗口大小。
向量库使用语义近似查找,文件库则是根据知识库说明和文件说明由大模型根据用户问题自动选择。
向量库是大多数场景下的首选,但是某些时候文件库是更好的选择。比如企业内部已经整理好的不同型号的产品规格文档,如果文件不大可以完整放入大模型上下文窗口,就可以选择文件库类型。因为不同型号的产品的规格文档可能大部分文字内容都一样,只有关键的数字不同的产品不一样。如果使用向量库进行语义匹配,容易导致查询时返回错误产品型号的情况。如果使用文件库,在查询时则根据文件描述来匹配用户的问题,更容易准确获取到相关信息。
向量嵌入模型
在选择向量库时,可以选择不同的向量嵌入模型来进行文档内容的向量化。平台提供两种向量嵌入模型:
- BGE-M3:专门为RAG优化的向量化嵌入模型,对中文的语义理解更优秀。
- Openai embedding: 性能全面的向量化模型
平台的缺省模型为BGE-M3
向量化策略
参考 向量化策略