RAG知识库
RAG技术
RAG(Retrieval-Augmented Generation)是一种结合信息检索和文本生成的技术。它的核心思想是:让生成模型在回答问题时,能主动从外部知识库中检索相关信息,从而生成更准确、更可靠的回答。
RAG技术可以很好的弥补大型语言模型也存在诸多不足:
- 知识的局限性:模型知识的广度获取严重依赖于训练数据集的广度,目前市面上大多数的大模型的训练集来源于网络公开数据集,对于一些内部数据、特定领域或高度专业化的知识,无从学习。
- 知识的滞后性:模型知识的获取是通过使用训练数据集训练获取的,模型训练后产生的一些新知识,模型是无法学习的,而大模型训练成本极高,不可能经常为了弥补知识而进行模型训练。
- 幻觉问题:所有的AI模型的底层原理都是基于数学概率,其模型输出实质上是一系列数值运算,大模型也不例外,所以它有时候会一本正经地胡说八道,尤其是在大模型自身不具备某一方面的知识或不擅长的场景。而这种幻觉问题的区分是比较困难的,因为它要求使用者自身具备相应领域的知识。
- 数据安全性:对于企业来说,数据安全至关重要,没有企业愿意承担数据泄露的风险,将自身的私域数据上传第三方平台进行训练。这也导致完全依赖通用大模型自身能力的应用方案不得不在数据安全和效果方面进行取舍。
RAG的工作流程
我们可以把RAG的工作流程分为5个阶段:
- 向量化阶段: 这一阶段的工作是利用嵌入模型(embeddings)把文本转化为高维向量,并保存到向量数据库中。
- 选库阶段:根据用户的问题,利用大语言模型的能力,选择合适的知识库。这一技术也被称为:查询路由(Query Routing)。
- 召回阶段:或者叫检索阶段,即将用户的问题也进行向量化,在向量数据库的高维向量空间里查找最接近的内容。
- 后处理阶段:当召回到多个上下文片段之后,可以进行适当的处理再提交给大语言模型进行生成。
- 生成阶段:大语言模型根据获取到的上下文片段来生成合适的文字。
煎蛋平台在这5个阶段都提供了丰富的配置选项,可以按照需求和文档内容来实现最优的RAG表现。
向量化阶段
在这一阶段,用户可以选择不同的向量模型和向量化策略。
向量模型(Embedding Model)是 RAG系统的核心组件之一,其性能直接影响 RAG 的最终效果。它的核心作用是将文本(问题、文档片段等)转换为高维向量(Embeddings),这些向量通过数学空间中的距离(如余弦相似度)反映语义关联性。优秀的向量模型能更精准地匹配问题与相关知识片段,避免漏检或误检。
煎蛋平台提供了两种向量模型:
- BGE-M3: BGE-M3 是由北京人工智能研究院和中国科学技术大学联合开发的新型嵌入模型,专门为 RAG 系统优化。其特点和强处在于具有多语言性、多功能性和多粒度性,支持超 100 种语言,能执行多种检索功能,可处理从短句到长文档的不同输入,在多项基准测试中表现出色。
- OpenAI text-embedding-3: 由微软 Azure OpenAI 服务提供,它能精准解析用户复杂问题,迅速从知识库中检索出高度匹配信息,极大提升检索效率与相关性 。其生成的嵌入向量对文本语义把握精准,利于大语言模型据此生成更贴合需求、准确详实的回答,有力增强 RAG 系统整体性能。
同时,如果用户有更好的向量模型选择,也可以自行通过 大模型管理 接入新的向量模型并在知识库系统中使用。
不同的文档内容往往需要不同的 向量化策略 ,才能实现更好的向量化效果。向量化策略 是通过配置不同的文件分块大小、重叠大小,调整向量化的具体内容等,来实现针对不同的文档内容和性质,获得更好的向量化效果。
煎蛋平台提供4种向量化策略,可以有效的处理不同的文档性质和内容。
- 原文分块向量化
- 父子分块向量化
- 分块总结向量化
- 假设问题向量化
具体的向量化策略的描述请参考向量化策略这一章节
选库阶段
当你问智能体关于国际政治的问题时,你不希望它去厨房菜谱里寻找答案。同样的,当你的用户向你的智能客服机器人提问关于产品性能的问题,你也不会希望它从企业的人事政策中找答案。所以,不同性质和类型的文档需要分别存放在不同的知识库中。然后根据用户的问题从对应的知识库中进行检索。
在煎蛋平台,我们可以在智能体的知识库设置里配置 选库策略 (或者也称为查询路由Query Routing)。一个智能体可以关联多个不同的知识库,智能体在进行回答时可以根据问题的内容、知识库的描述、以及所配置的选库策略找到合适的知识库进行检索。
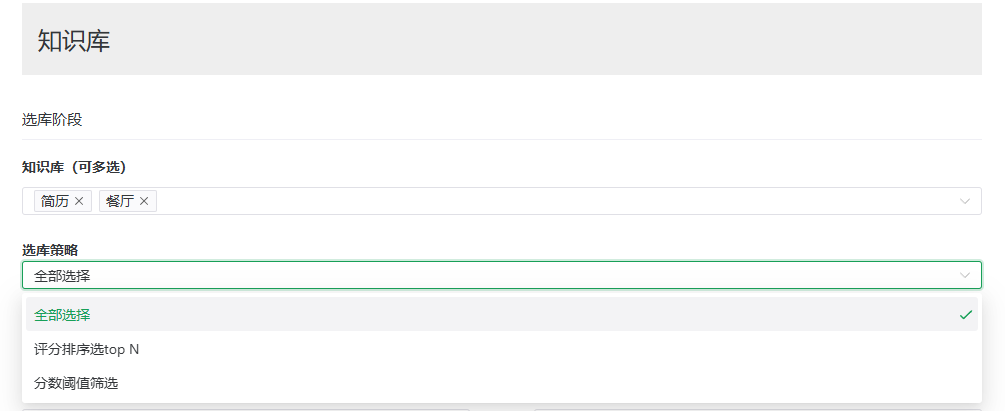
具体的选库策略的说明请参考[智能体知识库策略]这一章节。
召回阶段
或者称为检索阶段。在这一阶段你可以配置 每个知识库召回的上下文片段的数量、设置向量相似度的最小阈值(针对向量库)或者 文件描述评分的最小阈值(针对文件库)。你也可以开启 增强上下文选项,同时召回命中上下文的前后两个上下文。具体说明参见[智能体知识库策略]这一章节。
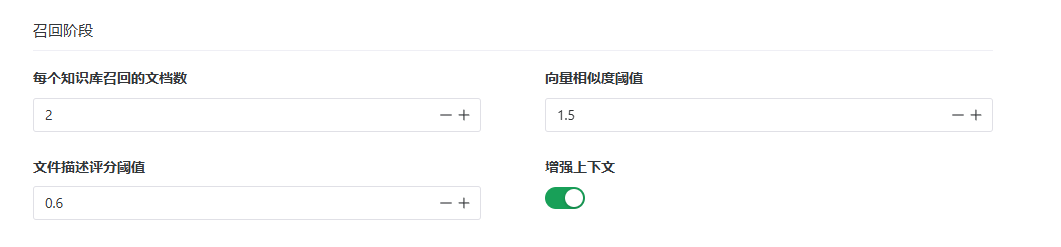
在召回阶段,还有一个设置可以影响检索命中的效果,即智能体设置里的 多轮对话时重新组织检索问题。这个设置可以把用户的问题用大语言模型重新进行组织,把用户的自然语言、代词等替换为更完整更明确的问题,再进行知识库检索。具体说明参考 智能体设置。

召回后处理阶段
从知识库召回相关的上下文片段之后,还可以进行把召回的上下文片段利用大语言模型进行评分排序,按照一定的策略来筛选之后再提交给大语言模型进行回答。这样做的好处有:
- 避免干扰信息:知识库检索总能找到一些相关内容,但这些内容到底有多相关呢?我们把那些与回答用户问题无关的数据点称为“干扰项”。它们可能会让结果变得混乱,甚至误导模型。
- 减少上下文长度:太长的上下文会影响大语言模型的响应速度,并且产生不必要的token费用。
后处理阶段所使用的模型可以和用来生成文本的大语言模型不同,通常推荐使用尺寸更小速度更快的模型比如: GPT-4o mini 或者 豆包1.5 lite
生成阶段
在大语言模型获得合适的上下文并进行回答时,还有一些设置可以让生成的信息更加有用:
- 上下文元数据:每个提供给大语言模型的上下文片段都会附加上这些元数据:
- 知识库名称
- 知识库说明
- 所属文件名称
- 所属文件说明
这些元数据都可以在知识库和文档里进行设置。有了这些元数据,大语言模型可以知道对应的上下文片段所属的知识库和文件信息,能够更好的回答用户的问题。
- 显示参考原文:在输出信息节点,你可以设置是否显示大语言模型回答所参考的的原文信息。有了这些参考原文,用户可以知道大语言模型的答案出处,增强采纳这些答案的信心。