Library
The Gendial platform includes a powerful and flexible library system, capable of meeting most internal knowledge base needs for businesses.
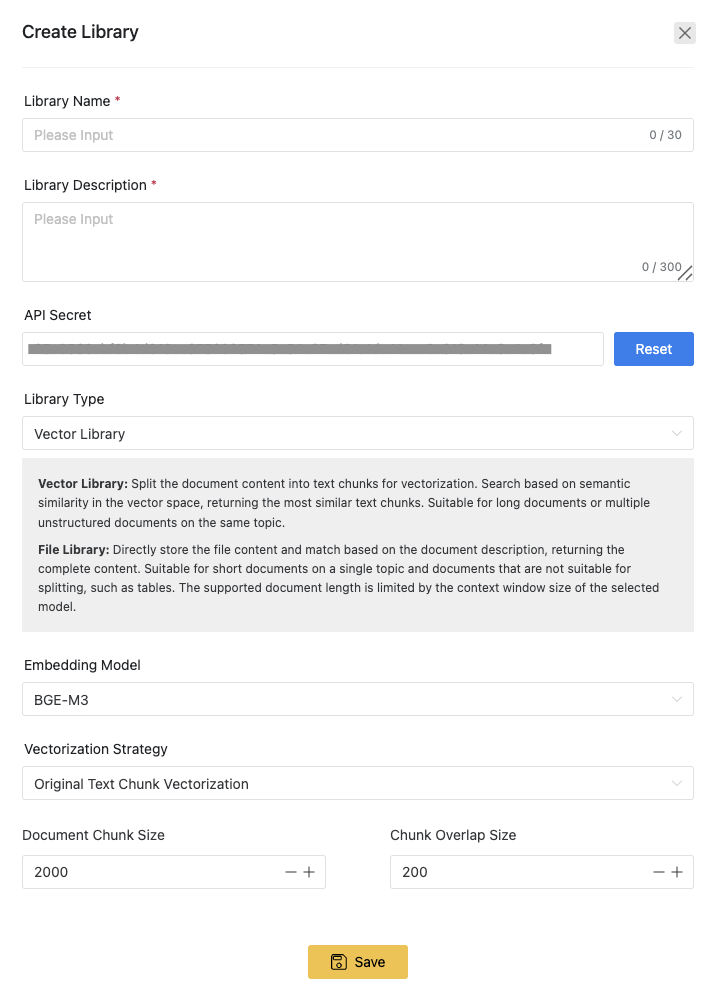
Library Settings
Library Name
The library name serves two purposes, in addition to helping with identification:
- When an AI agent is linked to multiple libraries, the library name will serve as an important condition for the AI to choose the appropriate base.
- The library name will be passed as part of the RAG context to the AI language model.
Therefore, it is important to choose an appropriate name for the library.
Library Description
The description outlines the contents of the library. Like the library name, the description also has two key uses:
- When an AI agent is linked to multiple libraries, the description serves as an important condition for the AI to select the correct base.
- The library description will be passed as part of the RAG context to the AI language model.
Therefore, it is important to describe the library accurately, as it will improve the quality of the RAG results.
API Key
The API key is used for authentication (as a bearer token) when using library-related APIs.
Library Type
The Gendial platform offers two types of libraries: vector-based and file-based.
Vector-Based Library: The document content is segmented into text blocks and quantified. Document matching is performed based on the semantic similarity in the vector space, and the most similar text blocks are returned. This is suitable for Q&A based on long documents or multiple unstructured documents on the same topic.
File-Based Library: Stores documents directly and matches them based on file descriptions, returning the full document content. This is ideal for short documents on a single topic, or documents that are not suitable for segmentation, such as tables. The length of the documents supported is limited by the context window size of the selected model.
The vector-based library uses semantic similarity for matching, while the file-based library uses large models to automatically select based on the library and file descriptions.
The vector-based library is preferred in most scenarios, but sometimes the file-based library is a better choice. For example, when a business has already organized specification documents for different product models, if the files are small enough to fit within the model’s context window, the file-based library can be chosen. This is because the specification documents for different product models often have nearly identical text content, with only key numbers differing between products. Using a vector-based system might result in incorrect product model queries due to semantic mismatches. The file-based system, on the other hand, allows for more accurate matching based on file descriptions, making it easier to obtain the relevant information.
Vector Embedding Model
When choosing a vector-based library, you can select different vector embedding models to vectorize the document content. The platform provides two vector embedding models:
- BGE-M3: A vector embedding model optimized for RAG, with better semantic understanding of Chinese.
- OpenAI Embedding: A comprehensive vectorization model.
The default model on the platform is BGE-M3
Vectorization Strategy
Refer to Vectorization Strategy