Library Strategy Settings
Here, we can set the library selection strategy, recall strategy, and post-recall processing strategy.
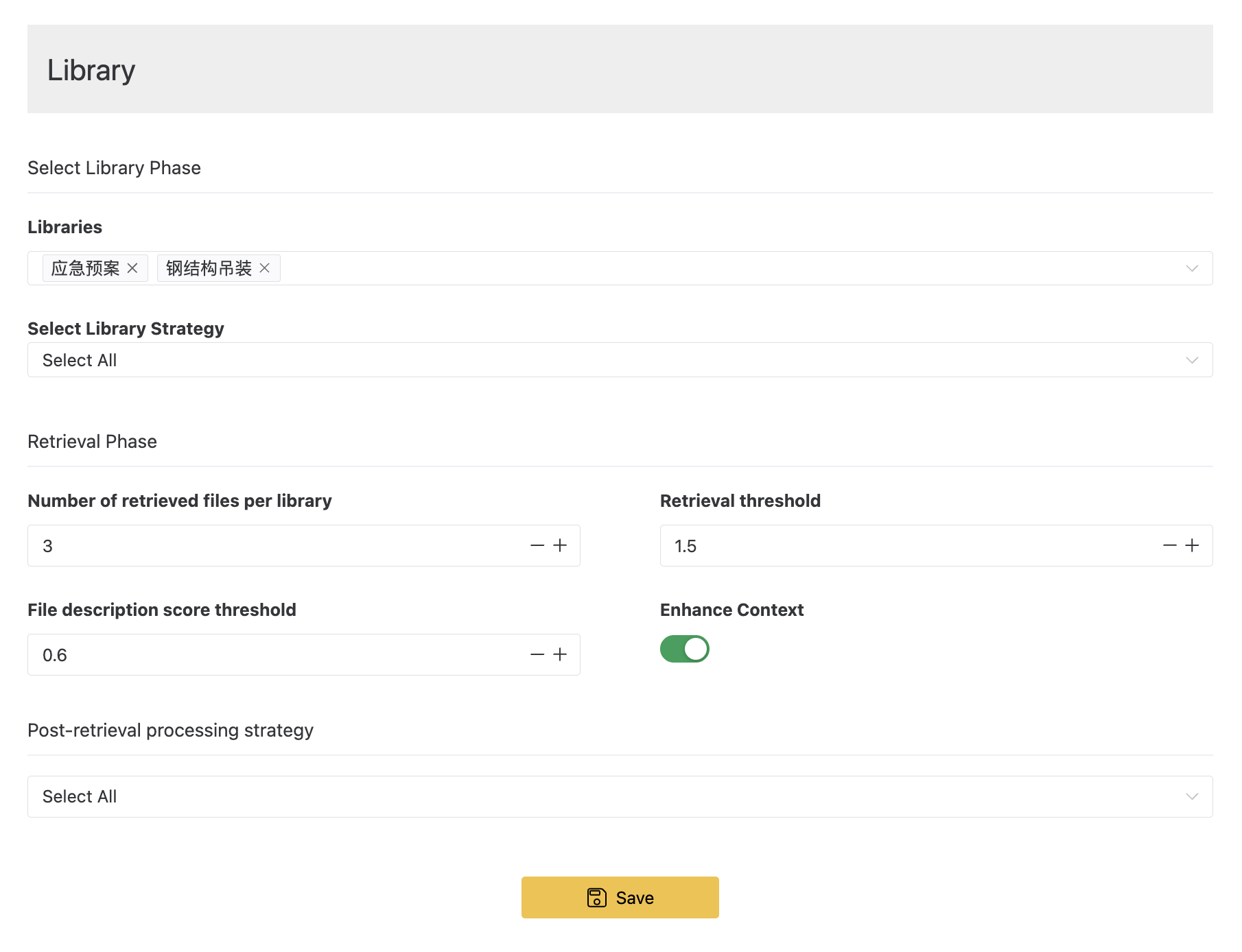
Library Selection Stage
Here you can set the libraries queried by the intelligent agent. Multiple libraries can be selected. If multiple libraries are chosen, the following selection strategies can be configured:
- Select All: Perform a search in all selected libraries.
- Score-Based Top N Selection: The large language model sorts the libraries based on their descriptions and then selects the top N.
- Score Threshold Filtering: The large language model sorts the libraries based on their descriptions and selects the ones with scores above a certain threshold.
Model used for score-based sorting: Set the large language model for selecting the libraries. It is recommended to use a smaller and faster model, such as GPT-4o mini.
Recall Stage
Set the intelligent agent's recall strategy.
- Number of Documents to Recall from Each library: The number of document chunks to recall from each library.
- Vector Similarity Threshold: (Only for vector libraries) Set the maximum similarity threshold for the vectors of the recalled document chunks. The lower the vector similarity, the better. Document chunks above this threshold will be excluded.
- File Description Score Threshold: (Only for file libraries) Set the minimum score threshold for the recalled file descriptions. The higher the score, the better. Files below this threshold will be excluded.
- Enhanced Context: (Only for vector libraries) Whether to recall the previous and next chunks of the matched document chunks.
Post-Recall Document Processing Strategy
Set the processing strategy after recall.
- Select All: All recalled document chunks are submitted to the large language model for generation.
- Score-Based Top N Selection: The large language model scores the content of the context and selects the top N.
- Score Threshold Filtering: The large language model scores the content of the context and selects those with scores above a certain threshold.
Model used for score-based sorting: Set the large language model used for scoring and filtering document chunks. It is recommended to use a smaller and faster model, such as GPT-4o mini.